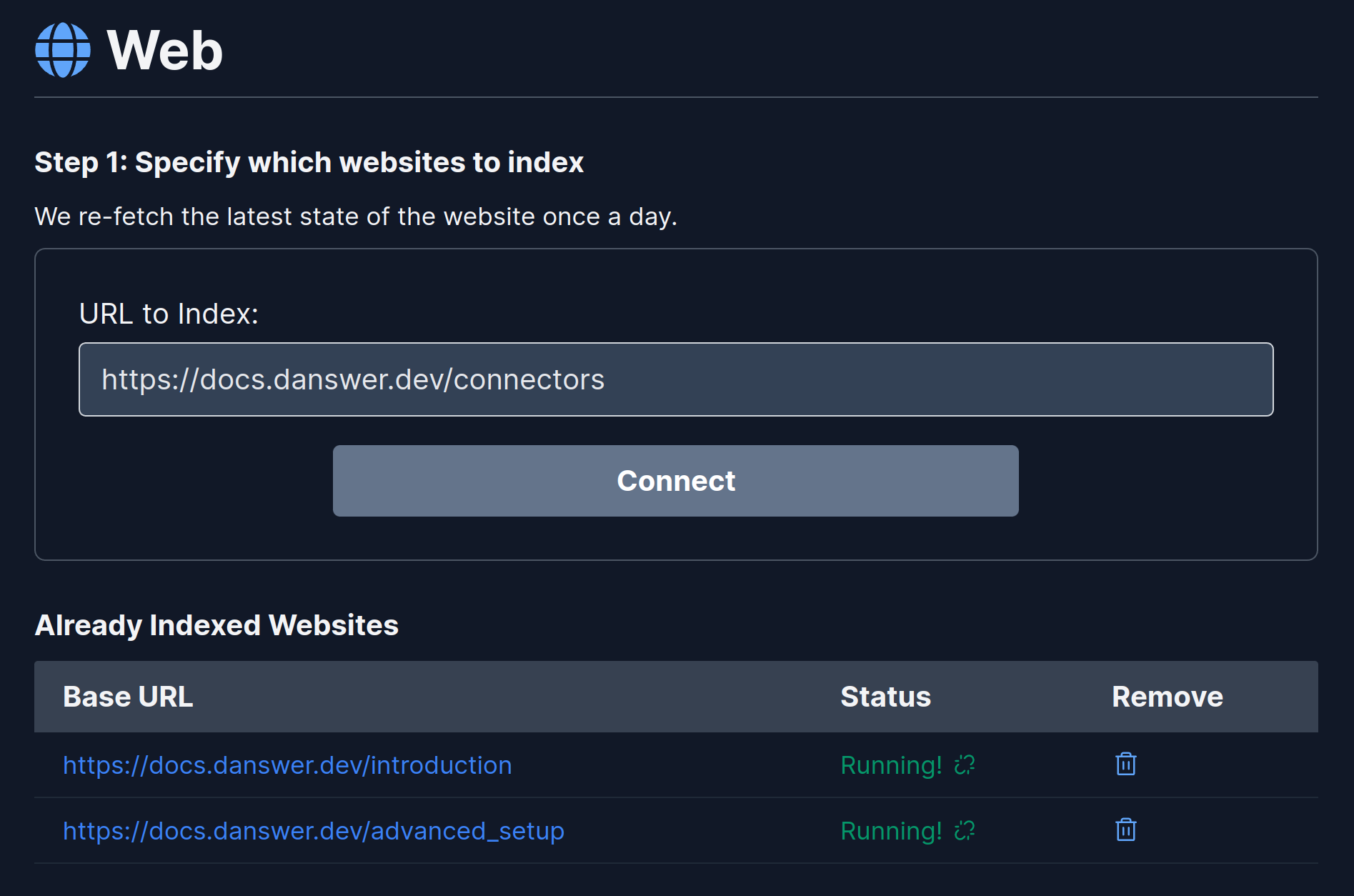
How it works
The Web Connector scrapes sites based on a base URL.- It only indexes files from the same domain and containing the same base path.
- It will index pages reachable via hyperlinks from the base URL.
- The text contents are cleaned up via some heuristics and some metadata such as the page Title is extracted.
Setting up
Authorization
- As long as the page is reachable, no additional authorization is necessary.
Indexing
To see the status of the indexing, visit the Connectors Status page (top left).